

深度學習一直是 AI 領域中主要的發展趨勢。而位置舊金山的 Open AI 最近開發了一套可判讀敘述性文字內容並自動生成對應圖像的系統「DALL.E」。
該公司負責人指出「DALL.E」是把西班牙超現實藝術家代表達利(Salvador Dalí ,1904-1989)和皮克斯動畫電影《瓦力(Wall-E)》結合起來,認為 DALL-E 具備理解文字意涵,並將該文字連結到合適的圖像,加以整合成為一幅作品。
例如:你輸入這段文字。一隻穿著西裝的皮卡丘騎著單輪車的插圖( an illustration of a pikachu in a suit riding a unicycle)。
DALL-E 系統將可以辨識這段文字中「皮卡丘」、「西裝、「單輪車」、「插畫」,並理解這些概念的因果關係,知道是皮卡丘穿著西裝騎在單輪車上,並創造出如下的圖像結果:

又如這個:穿著芭蕾舞短裙的熊貓寶寶揮舞著藍色光劍。DALL-E 可以理解光劍且是藍色的,由一隻小熊貓來揮動。
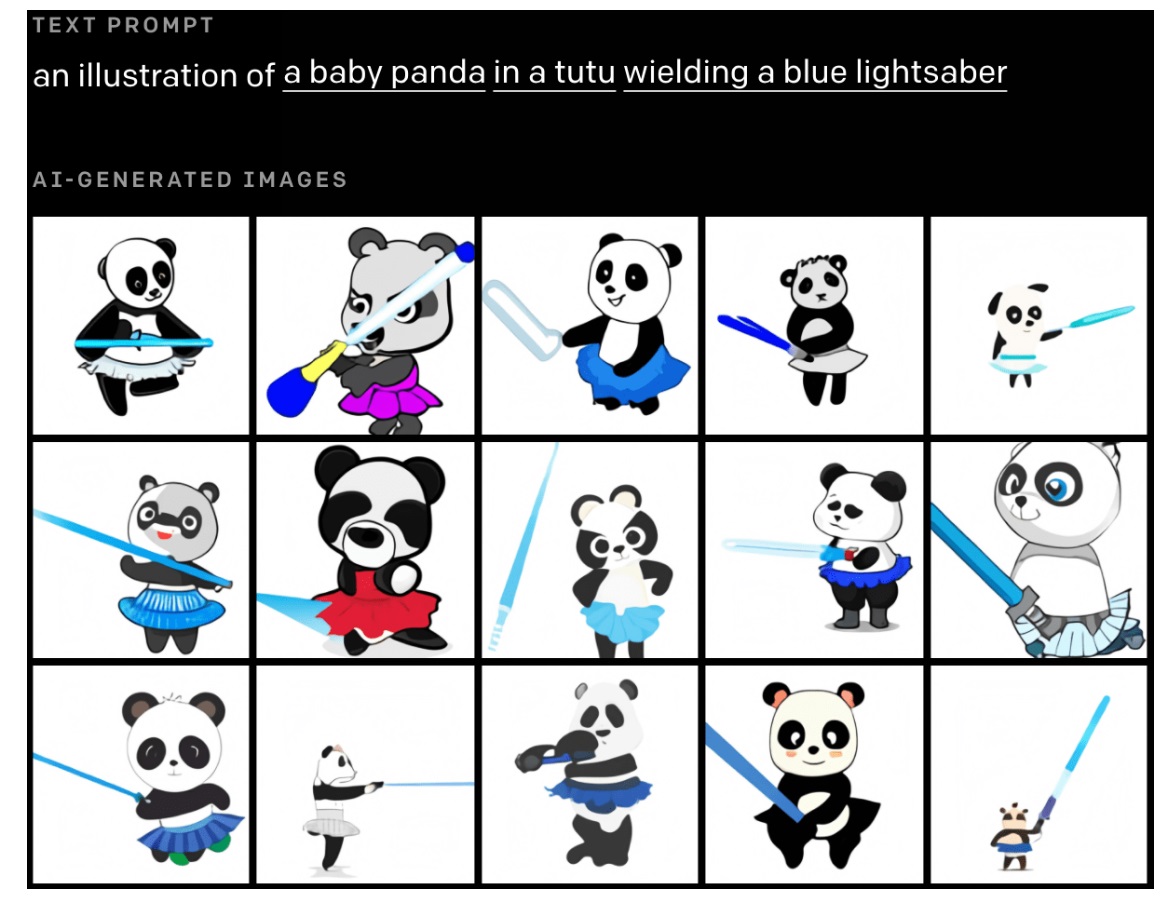
辨識系統可以用到更多範圍上,包含地理空間和時間。
例如下圖,你可以指定照片的位置地點與時間帶。我們經常使用 Google 之類的照片辨識系統,而透過越來越細緻精密的系統,或許更能馬上找出那個需要的關鍵在何時、何地、何方。
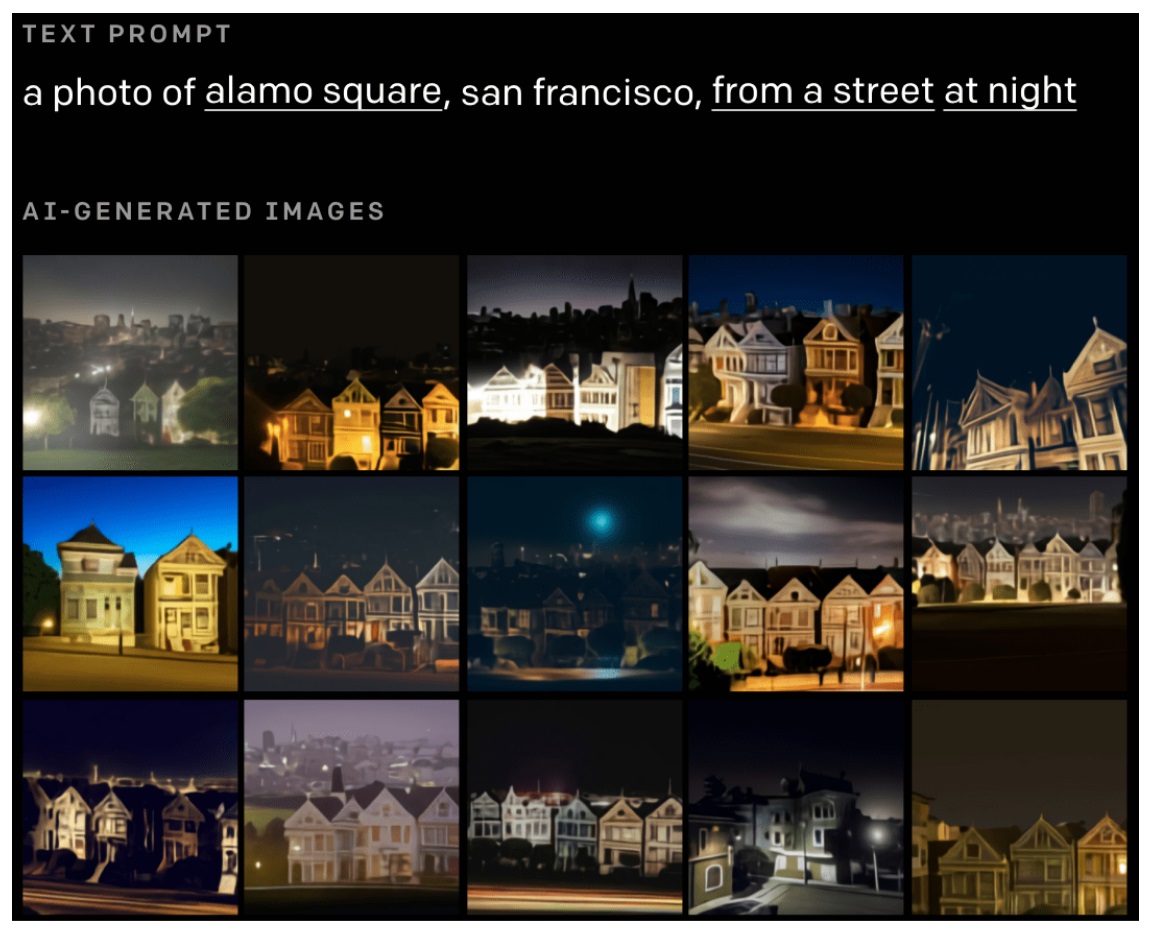
該公司表示,DALL-E 系統仍有一些缺陷且需要改進的地方。該系統在辨識各文字之間的關係時以及指定對象的屬性時,有時關連性仍會混亂,例如「在橋上」又同時「在橋下的水面上有天鵝經過」等等,而且當提示 寫入的字符串越長,成功率越低,

所以我們必須讓 DALL-E 理解每個條件文句之間的關係,有時是他們的空間並稱且連續的。例如:「戴紅色帽子,黃色手套,藍色襯衫和綠色褲子的刺猬」。為了正確地解釋這句話,
DALL·E 不僅必須正確地將每件服裝與動物組成,而且還必須形成關聯性(帽子是紅色)、(手套是黃色)、(襯衫是藍色)和(褲子是綠色),而且穿戴的位置是帽子在頭上、手套在手上、衣服在上半身,而褲子在下半身。

理解並辨識照片中文化意涵的認知,例如辨識「中國食物」時,DALL-E 需要辨識知道這個照片屬於「食物」,而且屬於中國文化。

DALL·E 是一個文字辨識與圖像學習系統,透過對於文字單詞的理解並重新解模,並根據條件句中的單詞從中找尋合適且對應的圖像進行辨識。或許,隨著 AI 深度學習的更進一步發展,未來我們可以透過文字或語言的幻想來操作視覺概念了,並將之具體化落實在現實設計中。
或許以後設計老闆說:「這邊的天空要藍一點,但又不要太藍,就是那種心情被遮蔽,光線穿不透打不開心房的那種藍」,這裡要有 60%後現代風加上 35% 復古風,再加 5%超現實藝術感覺時,
你就把他交給 DALL-E 去處理。
SOURCE
https://openai.com/blog/dall-e/
https://thenextweb.com/neural/2021/01/06/say-hello-to-openais-dall-e-a-gpt-3-powered-bot-that-creates-weird-images-from-text/
http://big5.ftchinese.com/story/001090931?exclusive





